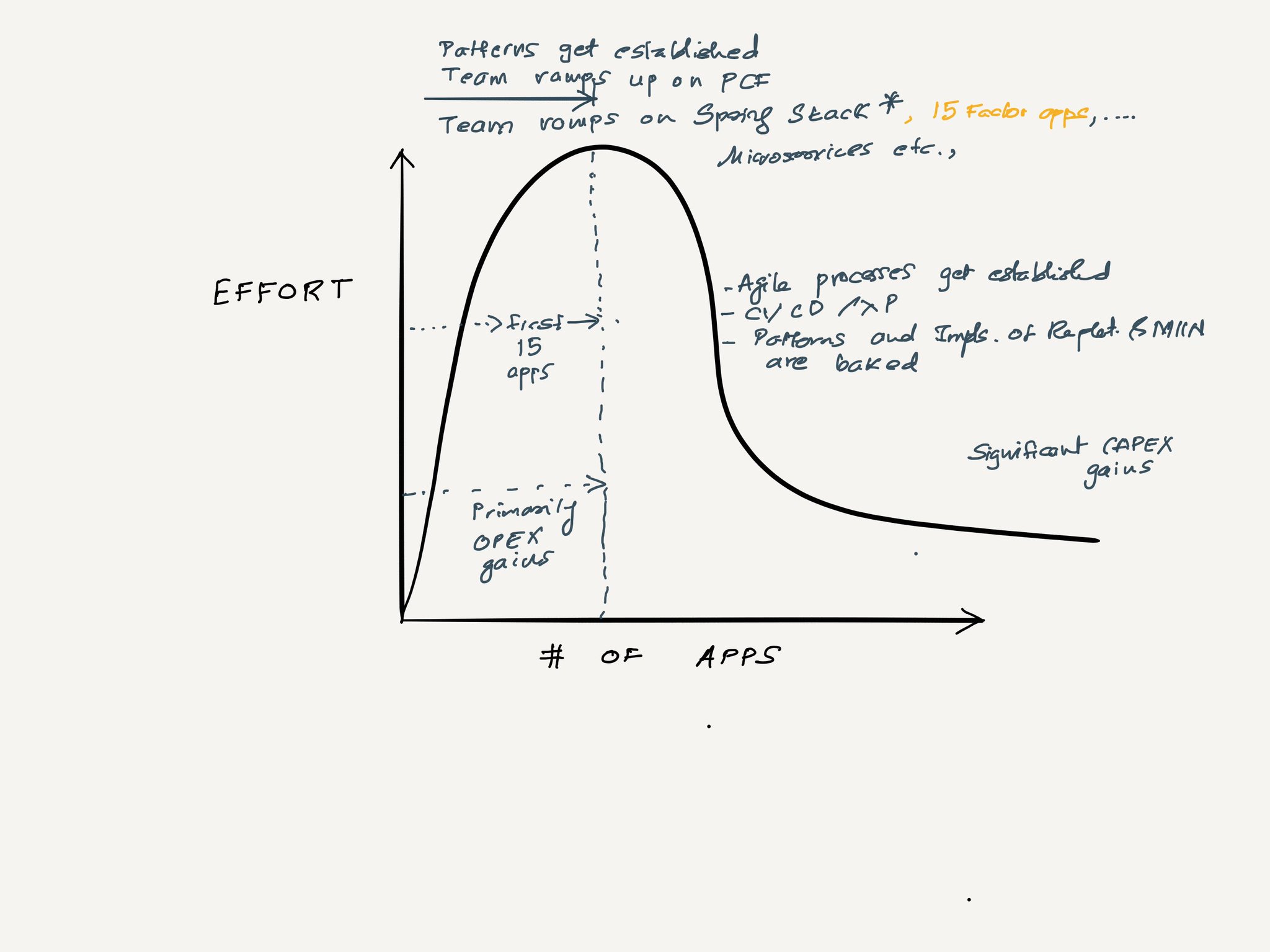
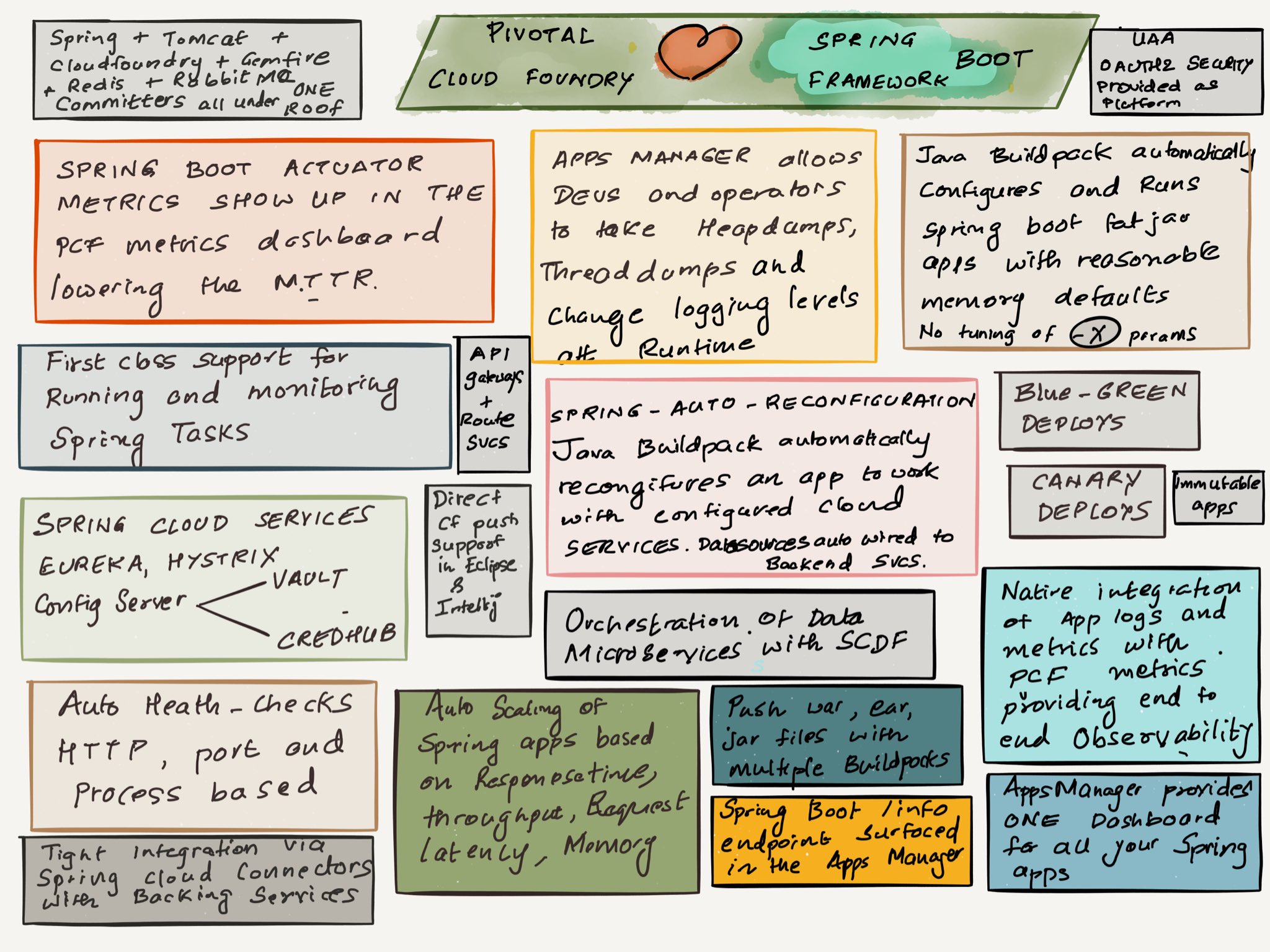
Q. When do we modify an existing service for a new consumer vs. build a new service for that consumer? For example, if a service is returning back data a certain way and a new consumer comes along and wants to see the data in a slightly different way (with potentially more data), do we modify the existing service or build a completely new service?
When a consumer for a existing service comes along we build an adapter for the new consumer that adapts the data for the new consumer. We modify an existing service aggregates and entities based on the business invariants of the domain. We never modify our internal model for an external service. Splitting a monolith is all about identifying seams. There are two primary approaches to figure out the seams of your application with their accompanying advantages and pitfalls.
Top-Down: This is an approach of decomposition driven from the top using tactical techniques of DDD like Event Storming to identify the bounded contexts and their respective context mappings. Usually this yields a desired model of microservices for the monolith. Translating from current fucked up state to desired state is like landing a plane on a runway requiring rigorous practice of Lean engineering principles (MVPs, Iteration, Feedback). The exercises of event storming and modeling with DDD typically result in buzz-word compliant CQRS and Event Sourcing implementations. CQRS/ES are super
difficult to implement in greenfield let alone as a bridge from brownfield apps. Its important to keep focus on the goals of breaking the megalith and not get enamored by the new and shiny.
Bottom-Up: This approach of decomposition is driven by current pain points of the monolith. For instance separating the UI from backend processing. Separating batch from real time processing. Here you are letting technology and your existing domain expertise break the app apart. DDD and domains informs your decomposition; however this is a code led desplunking effort. Another way I have seen this implemented is that a vertical slice of business capability is carved out of the monolith and this vertical slice of function is then used to modernize all layers of technical stack including web and backend tiers. Code driven decomposition is made difficult by the fact that humans can keep only so much information in the head at one time. It is very easy to get lost in the forest and keep walking in circles and NEVER emerge out of the woods. Techniques like TDD, Iterative development and Mikado method will help keep you on the right path out of the forest.
Q. What are our service versioning strategies when making changes to an existing service that supports multiple clients?
When a service is used by multiple clients ideally ALL changes to the service need to be backwards compatible. If this is not possible then implement [
parallel change]. Semantically version all changes and evolutions to the service schema and APIs. There may be times when you need to make a breaking change. When this happens, you need to ensure that you never do anything that will cause your API consumers to fix the code. It is important to establish an API Versioning Strategy 1. Establish proper expectations that the API will change 2. API is a contract and cannot be broken with a new version release. API versioning will follow [
semver] guidelines i.e. Non breaking changes result in a minor version bump. Breaking changes result in a new major version. API versioning can be implemented using 1. Resource Versioning 2. URI versioning 3. Hostname versioning. [
api-versioning-when-how]
Q. How do we coordinate multiple teams switching over to a modernized service at different times?
The key here is to insert [
consumer driven contracts]. Each team onboarded establishes a consumer driven contract with the supplier service. This give us the fine-grained insight and rapid feedback when the modernized service requires to plan changes and assess its impact on applications currently in production. The contracts established here serve as insurance when new teams onboard or when the modernized service evolves.
Q. As we are in the process of modernizing a service (this process could take multiple years) it’s possible that new requirements come along that need to be implemented. How do we effectively identify that these requirements need to be implemented in both the legacy service and the modernized service
You could follow a couple of policies here
1. Never modify the legacy service. All new function ONLY gets added to the modernized service with suitable bridges, adapters and anti-corruption layers to the legacy service.
2. First modify the modernized service and then take the lessons and apply them to the legacy code ideally as a standalone component or module of the legacy system.
3. Leverage feature flags allowing you to turn off features in the legacy service once the feature is completely migrated to the modernized service.
Q. What is the migration strategy for cutting over clients to the modernized service? For example, today we usually incrementally switch clients over to a new service, usually by jurisdiction. Is this an effective strategy?
Introduce a layer of abstraction. Have both services implement the facade. Gradually switch clients to the modernized service that implements the same facade as the old code. Clients could be migrated by any grouping criteria. Use techniques like dynamic routing with API Gateways, Blue/Green, Context Path Routing and canary releases to reduce the impact of cutover to the modernized service. Use feature flags to control the flow of inbound clients.
Q. How do we manage the migration of data from the legacy services to the modernized services? Some of our tables have millions of records and hundreds of columns.
[
Branch-by-abstraction] enables rapid deployment with feature development that requires large changes to the codebase. For example, consider the delicate issue of migrating data from an existing store to a new one. This can be broken down as follows:
- Require a transition period during which both the original and new schemas exist in production
- Encapsulate access to the data in an appropriate data type. Expose a Facade service to encapsulate DB changes.
- Modify the implementation to store data in both the old and the new stores. Move logic and constraints to the edge aka services
- Bulk migrate existing data from the old store to the new store.
- This is done in the background in parallel to writing new data to both stores.
- Modify the implementation to read from both stores and compare the obtained data. Implement retry and compensations. Database Transformation Patterns cataloged like Data sync, data replication and migrating data.
- Leverage techniques like TCP Proxy for JDBC to understand the flow of data and transparently intercept traffic. Use Change Data Capture tooling to populate alternate datastores.
- When convinced that the new store is operating as intended, switch to using the new store exclusively (the old store may be maintained for some time to safeguard against unforeseen problems).
Managing Persistence: You will need to choose between creating a new DB or letting the old and new implementations share the same datastore. Separating the DBs is more complex if you need to keep them in sync, but it gives you a lot more freedom. If your old and new applications share a datastore, you’ll need to build a translation layer to translate between the old and new models. If you give your old and new applications separate datastores, be prepared to invest a lot of effort in tooling to synchronize the two DBs. If your DB synchronization mechanism writes directly to the DB, be careful you don’t violate any assumptions the application makes about being the sole writer.[
Re-engineering Legacy Software]. Splitting data for microservices involves breaking foreign key relationships and managing constraints in the resulting services rather than at the database level. For shared mutable data you may need to split the schemas , keep the service together before splitting the application out into separate microservices. By splitting the schemas but keeping the application code together, we can revert our changes or continue to tweak things without impacting any consumers of our service. Once we are satisfied that the DB separation makes sense, we can then think about splitting out the application code into two services.[
Refactoring Databases]
Q. What happens when a journey/business capability team has a service that multiple teams want to use?
Establish appropriate provider and consumer contracts with downstream consumers and expose a consumable API. The downstream consumers will conform to the model exposed by the desired Journey services.
Q. What is our strategy for figuring out who the existing clients are?
Insert transparent proxies in the routing flow to determine all the downstream consumers. Leverage edge entry controller patterns like bridge, router, proxy, facade and backends 4 frontends.
Q. What are some technical issues we may run into when a legacy service tries consuming a next generation service?
Model mismatch, Mapping and translation, data duplication, unnecessary hops, data consistency.
Q. Which services should we target for modernization ?
Modernization has to start from some point. There are various starting points. You should avoid analysis-paralysis and quickly start learning to inform the refactoring of the rest of the code. Perhaps a core domain that is upstream to a number of services would be a better starting point.
Q. We currently operate on a monthly release cycle. At any given time, we will have 8 different environments to support 2 different monthly releases. We will not be able to completely break away from this release schedule for years.
Understand that this is more of a DevOps issue. You need to transform the value chain following this playbook created by
Josh Kruck
- Identify a single product to work with / go after
- Put all the people responsible for the thing together (design, dev, qa, arch, pm etc), permanently
- Identify the thing that 1. is done most often and 2. is repeated most often (use a 2x2)
- Fix it, solution can totally be a one off as long as you learn from it
- Repeat 3&4.
Q. What does the dialog look like with the current consumers of legacy services when we are trying to move them to a modernized a capability?
Surface the pain first. Talk to them about existing pain points and integration down the road. Provide a roadmap of expected changes to the API and policies for evolving the service. Establish provider and supplier contracts and a protocol for communication that will survive schema evolution.
Q. We have over 100s of different service operations today. So far our strategy has been to increment over each one of these operations based off of a very focused isolated use case and eventually reach out to other clients to understand their needs.
You should take the time and examine these discrete operations and find opportunities to align and refactor them along bounded contexts. Consumers need to call Car.start() and not Car.getEngine().start(). Tell the API to carry out a capability rather than orchestrate discrete flows with data.
Q. Performance testing strategies across the entire ecosystem
Unit tests, Gatling performance tests, WireMock Tests, Service Virtualization with
Hoverfly, Synthetic tests in production, SOAP-UI tests, Selenium web driver tests, IntegrationTests, Functional Tests, Stress tests, Chaos tests, PEN Tests, User acceptance Tests, A/B tests. [
see]